Automatic Differentiation
Motivation
It supports a lot of modern machine learning by allowing quick differentiation of complex mathematical functions. The 1st order optimization methods are ubiquitous in finding parameters of functions (not only in deep learning).
AD is interesting to study from both mathermatical and implementation perspective, since different approaches comes with different trade-offs. Julia offers many implementations (some of them are not maintained anymore), as it showed to implement (simple) AD is relatively simple.
We (authors of this course) believe that it is good to understand (at least roughly), how the methods work in order to use them effectively in your work.
Julia is unique in the effort separating definitions of AD rules from AD engines that use those rules to perform the AD and the backend which executes the rules This allows authors of generic libraries to add new rules that would be compatible with many frameworks. See juliadiff.org for a list.
Theory
The differentiation is routine process, as most of the time we break complicated functions down into small pieces that we know, how to differentiate and from that to assemble the gradient of the complex function back. Thus, the essential piece is the differentiation of the composed function
which is computed by chainrule. Before we dive into the details, let's define the notation, which for the sake of clarity needs to be precise. The gradient of function
For a composed function
where
How
If
, then is a real number and we live in a high-school world, where it was sufficient to multiply real numbers. If
, then is a matrix with rows and columns.
The computation of gradient
computing Jacobians
multiplication of Jacobians as it holds that
.
The complexity of the computation (at least one part of it) is therefore determined by the Matrix multiplication, which is generally expensive, as theoretically it has complexity at least
Jacobians are multiplied from right to left as
which has the advantage when the input dimension of is smaller than the output dimension, . - referred to as the FORWARD MODE Jacobians are multiplied from left to right as
which has the advantage when the input dimension of is larger than the output dimension, . - referred to as the BACKWARD MODE
The ubiquitous in machine learning to minimization of a scalar (loss) function of a large number of parameters. Also notice that for f of certain structures, it pays-off to do a mixed-mode AD, where some parts are done using forward diff and some parts using reverse diff.
Example
Let's workout an example
How it maps to the notation we have used above? Particularly, what are
The corresponding jacobians are
and for the gradient it holds that
Note that from theoretical point of view this decomposition of a function is not unique, however as we will see later it usually given by the computational graph in a particular language/environment.
Calculation of the Forward mode
In theory, we can calculate the gradient using forward mode as follows Initialize the Jacobian of i from n down to 1 as
calculate the next intermediate output as
calculate Jacobian
push forward the gradient as
Notice that
on the very end, we are left with
and with , which is the gradient we wanted to calculate; if
yis a scalar, thenis a matrix with single row the Jacobian and the output of the function is calculated in one sweep.
The above is an idealized computation. The real implementation is a bit different, as we will see later.
Implementation of the forward mode using Dual numbers
Forward modes need to keep track of the output of the function and of the derivative at each computation step in the computation of the complicated function
where
How are dual numbers related to differentiation?
Let's evaluate the above equations at
and notice that terms
meaning that at this moment we have obtained gradients with respect to
All above functions
which is
Does dual numbers work universally?
Let's first work out polynomial. Let's assume the polynomial
and compute its value at
where in the multiplier of
Let's now consider a general function
where all higher order terms can be dropped because
Implementing Dual number with Julia
To demonstrate the simplicity of Dual numbers, consider following definition of Dual numbers, where we define a new number type and overload functions +, -, *, and /. In Julia, this reads:
struct Dual{T<:Number} <: Number
x::T
d::T
end
Base.:+(a::Dual, b::Dual) = Dual(a.x+b.x, a.d+b.d)
Base.:-(a::Dual, b::Dual) = Dual(a.x-b.x, a.d-b.d)
Base.:/(a::Dual, b::Dual) = Dual(a.x/b.x, (a.d*b.x - a.x*b.d)/b.x^2) # recall (a/b) = a/b + (a'b - ab')/b^2 ϵ
Base.:*(a::Dual, b::Dual) = Dual(a.x*b.x, a.d*b.x + a.x*b.d)
# Let's define some promotion rules
Dual(x::S, d::T) where {S<:Number, T<:Number} = Dual{promote_type(S, T)}(x, d)
Dual(x::Number) = Dual(x, zero(typeof(x)))
Dual{T}(x::Number) where {T} = Dual(T(x), zero(T))
Base.promote_rule(::Type{Dual{T}}, ::Type{S}) where {T<:Number,S<:Number} = Dual{promote_type(T,S)}
Base.promote_rule(::Type{Dual{T}}, ::Type{Dual{S}}) where {T<:Number,S<:Number} = Dual{promote_type(T,S)}
# and define api for forward differentionation
forward_diff(f::Function, x::Real) = _dual(f(Dual(x,1.0)))
_dual(x::Dual) = x.d
_dual(x::Vector) = _dual.(x)_dual (generic function with 2 methods)And let's test the Babylonian Square Root (an algorithm to compute
julia> babysqrt(x, t=(1+x)/2, n=10) = n==0 ? t : babysqrt(x, (t+x/t)/2, n-1)
babysqrt (generic function with 3 methods)
julia> forward_diff(babysqrt, 2)
0.35355339059327373
julia> forward_diff(babysqrt, 2) ≈ 1/(2sqrt(2))
true
julia> forward_diff(x -> [1 + x, 5x, 5/x], 2)
3-element Vector{Float64}:
1.0
5.0
-1.25We now compare the analytic solution to values computed by the forward_diff and byt he finite differencing
julia> using FiniteDifferences
ERROR: ArgumentError: Package FiniteDifferences not found in current path.
- Run `import Pkg; Pkg.add("FiniteDifferences")` to install the FiniteDifferences package.
julia> forward_dsqrt(x) = forward_diff(babysqrt,x)
forward_dsqrt (generic function with 1 method)
julia> analytc_dsqrt(x) = 1/(2babysqrt(x))
analytc_dsqrt (generic function with 1 method)
julia> forward_dsqrt(2.0)
0.35355339059327373
julia> analytc_dsqrt(2.0)
0.3535533905932738
julia> central_fdm(5, 1)(babysqrt, 2.0)
ERROR: UndefVarError: `central_fdm` not defined in `Main`
Suggestion: check for spelling errors or missing imports.plot(0.0:0.01:2, babysqrt, label="f(x) = babysqrt(x)", lw=3)
plot!(0.1:0.01:2, analytc_dsqrt, label="Analytic f'", ls=:dot, lw=3)
plot!(0.1:0.01:2, forward_dsqrt, label="Dual Forward Mode f'", lw=3, ls=:dash)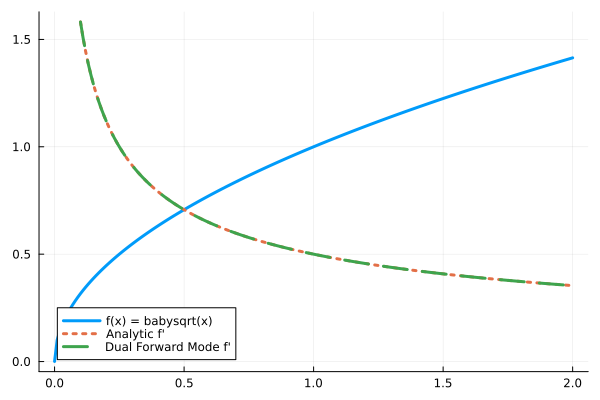
Takeaways
Forward mode
is obtained simply by pushing a DualthroughbabysqrtTo make the forward diff work in Julia, we only need to overload a few operators for forward mode AD to work on any function. Therefore the name of the approach is called operator overloading.
For vector valued function we can use Hyperduals
Forward diff can differentiation through the
setindex!(called each time an element is assigned to a place in array, e.g.x = [1,2,3]; x[2] = 1)ForwardDiff is implemented in
ForwardDiff.jl, which might appear to be neglected, but the truth is that it is very stable and general implementation.ForwardDiff does not have to be implemented through Dual numbers. It can be implemented similarly to ReverseDiff through multiplication of Jacobians, which is what is the community work on now (in
Mooncake,Zygotewith rules defined inChainRules).
Reverse mode
In reverse mode, the computation of the gradient follow the opposite order. We initialize the computation by setting
The complete reverse mode algorithm therefore proceeds as
- Forward pass: iterate
ifromndown to1as
- calculate the next intermediate output as
- Backward pass: iterate
ifrom1down tonas
calculate Jacobian
at point pull back the gradient as
The need to store intermediate outs has a huge impact on memory requirements, which particularly on GPU is a big deal. Recall few lectures ago we have been discussing how excessive memory allocations can be damaging for performance, here we are given an algorithm where the excessive allocation is by design.
Tricks to decrease memory consumptions
- Define custom rules over large functional blocks. For example while we can auto-grad (in theory) matrix product, it is much more efficient to define make a matrix multiplication as one large function, for which we define Jacobians (note that by doing so, we can dispatch on Blas). e.g
When differentiating Invertible functions, calculate intermediate outputs from the output. This can lead to huge performance gain, as all data needed for computations are in caches.
Checkpointing does not store intermediate ouputs after larger sequence of operations. When they are needed for forward pass, they are recalculated on demand.
Most reverse mode AD engines does not support mutating values of arrays (setindex! in julia). This is related to the memory consumption, where after every setindex! you need in theory save the full matrix. Enzyme differentiating directly LLVM code supports this, since in LLVM every variable is assigned just once. Mooncake supports this by saving values needed to reconstruct the arrays. ForwardDiff methods does not suffer this problem, as the gradient is computed at the time of the values.
Info
Reverse mode AD was first published in 1976 by Seppo Linnainmaa[1], a finnish computer scientist. It was popularized in the end of 80s when applied to training multi-layer perceptrons, which gave rise to the famous backpropagation algorithm[2], which is a special case of reverse mode AD.
Info
The terminology in automatic differentiation is everything but fixed. The community around ChainRules.jl went a great length to use something reasonable. They use pullback for a function realizing vector-Jacobian product in the reverse-diff reminding that the gradient is pulled back to the origin of the computation. The use pushforward to denote the same operation in the ForwardDiff, as the gradient is push forward through the computation.
Implementation details of reverse AD
Reverse-mode AD needs to record operations over variables when computing the value of a differentiated function, such that it can walk back when computing the gradient. This record is called tape, but it is effectively a directed acyclic graph. The construction of the tape can be either explicit or implicit. The code computing the gradient can be produced by operator-overloading or code-rewriting techniques. This give rise of four different takes on AD, and Julia has libraries for alll four.
Yota.jl: explict tape, code-rewritingTracker.jl,AutoGrad.jl: implict tape, operator overloadingReverseDiff.jl: explict tape, operator overloadingZygote.jl: implict tape, code-rewriting
Graph-based AD
In Graph-based approach, we start with a complete knowledge of the computation graph (which is known in many cases like classical neural networks) and augment it with nodes representing the computation of the computation of the gradient (backward path). We need to be careful to add all edges representing the flow of information needed to calculate the gradient. Once the computation graph is augmented, we can find the subgraph needed to compute the desired node(s).
Recall the example from the beginning of the lecture

where arrows
We start from the top and add a node calculating

We connect it with the output of

We continue with the same process with

containing the desired nodes
This approach to AD has been taken for example by Theano, TensorFlow, and JAX. In Tensorflow when you use functions like tf.mul( a, b ) or tf.add(a,b), you are not performing the computation in Python, but you are building the computational graph shown as above. You can then compute the values using tf.run with a desired inputs, but you are in fact computing the values in a different interpreter / compiler then in python. PyTorch now does this in compiled mode.
Advantages:
Knowing the computational graph in advance is great, as you can do expensive optimization steps to simplify the graph.
The computational graph have a simple semantics (limited support for loops, branches, no objects), and the compiler is therefore simpler than the compiler of full languages.
Since the computation of gradient augments the graph, you can run the process again to obtain higher order gradients.
TensorFlow allows you to specialize on sizes of Tensors, which means that it knows precisely how much memory you will need and where, which decreases the number of allocations. This is quite important in GPU.
Disadvantages:
You are restricted to fixed computation graph. It is generally difficult to implement
iforwhile, and hence to change the computation according to values computed during the forward pass.Development and debugging can be difficult, since you are not developing the computation graph in the host language.
Exploiting within computation graph parallelism might be difficult.
Comments:
DaggerFLux.jl use this approach to perform model-based paralelism, where parts of the computation graph (and especially parameters) can reside on different machines.
Umlaut.jl allows to easily obtain the tape through tracing of the execution of a function, which can be then used to implement the AD as described above (see Yota's documentation for complete example).
julia> using Umlaut
julia> g(x, y) = x * y
g (generic function with 1 method)
julia> f(x, y) = g(x, y)+sin(x)
f (generic function with 1 method)
julia> tape = trace(f, 1.0, 2.0)[2]
ERROR: FieldError: type Compiler.IRCode has no field `linetable`, available fields: `stmts`, `argtypes`, `sptypes`, `debuginfo`, `cfg`, `new_nodes`, `meta`, `valid_worlds`Yota.jl use the tape to generate the gradient as
julia> tape = Yota.gradtape(f, 1.0, 2.0; seed=1.0)
ERROR: UndefVarError: `Yota` not defined in `Main`
Suggestion: check for spelling errors or missing imports.
julia> Umlaut.to_expr(tape)
ERROR: UndefVarError: `tape` not defined in `Main`
Suggestion: add an appropriate import or assignment. This global was declared but not assigned.Tracking-based AD
Alternative to static-graph based methods are methods, which builds the graph during invocation of functions and then use this dynamically built graph to know, how to compute the gradient. The dynamically built graph is frequently called tape. This approach is used by popular libraries like PyTorch, AutoGrad, and Chainer in Python ecosystem, or by Tracker.jl (Flux.jl's former AD backend), ReverseDiff.jl, and AutoGrad.jl (Knet.jl's AD backend) in Julia. This type of AD systems is also called operator overloading, since in order to record the operations performed on the arguments we need to replace/wrap the original implementation.
How do we build the tracing? Let's take a look what ReverseDiff.jl is doing. It defines TrackedArray (it also defines TrackedReal, but TrackedArray is more interesting) as
struct TrackedArray{T,N,V<:AbstractArray{T,N}} <: AbstractArray{T,N}
value::V
deriv::Union{Nothing,V}
tape::Vector{Any}
string_tape::String
endwhere in
valueit stores the value of the arrayderivwill hold the gradient of the tracked arraytapeof will log operations performed with the tracked array, such that we can calculate the gradient as a sum of operations performed over the tape.
What do we need to store on the tape? Let's denote as TrackedArray. The gradient with respect to some output InstructionTape will therefore contain a reference to TrackedArray and where we know deriv field) and we also need to a method calculating
TrackedArray(a::AbstractArray, string_tape::String = "") = TrackedArray(a, similar(a) .= 0, [], string_tape)
TrackedMatrix{T,V} = TrackedArray{T,2,V} where {T,V<:AbstractMatrix{T}}
TrackedVector{T,V} = TrackedArray{T,1,V} where {T,V<:AbstractVector{T}}
Base.show(io::IO, ::MIME"text/plain", a::TrackedArray) = show(io, a)
Base.show(io::IO, a::TrackedArray) = print(io, "TrackedArray($(size(a.value)))")
value(A::TrackedArray) = A.value
value(A) = A
track(A, string_tape = "") = TrackedArray(A, string_tape)
track(a::Number, string_tape) = TrackedArray(reshape([a], 1, 1), string_tape)
import Base: +, *
function *(A::TrackedMatrix, B::TrackedMatrix)
a, b = value.((A, B))
C = TrackedArray(a * b, "($(A.string_tape) * $(B.string_tape))")
push!(A.tape, (C, ∂C -> ∂C * b'))
push!(B.tape, (C, ∂C -> a' * ∂C))
C
end
function *(A::TrackedMatrix, B::AbstractMatrix)
a, b = value.((A, B))
C = TrackedArray(a * b, "($(A.string_tape) * B)")
push!(A.tape, (C, ∂C -> ∂C * b'))
C
end
function *(A::Matrix, B::TrackedMatrix)
a, b = value.((A, B))
C = TrackedArray(a * b, "A * $(B.string_tape)")
push!(A.tape, (C, ∂C -> ∂C * b'))
C
end
function +(A::TrackedMatrix, B::TrackedMatrix)
C = TrackedArray(value(A) + value(B), "($(A.string_tape) + $(B.string_tape))")
push!(A.tape, (C, ∂C -> ∂C))
push!(B.tape, (C, ∂C -> ∂C))
C
end
function msin(A::TrackedMatrix)
a = value(A)
C = TrackedArray(sin.(a), "sin($(A.string_tape))")
push!(A.tape, (C, ∂C -> cos.(a) .* ∂C))
C
endLet's observe that the operations are recorded on the tape as they should
a = rand()
b = rand()
A = track(a, "A")
B = track(b, "B")
# R = A * B + msin(A)
C = A * B
A.tape
B.tape
C.string_tape
R = C + msin(A)
A.tape
B.tape
R.string_tapeLet's now implement a function that will recursively calculate the gradient of a term of interest. It goes over its childs, if they not have calculated the gradients, calculate it, otherwise it adds it to its own after if not, ask them to calculate the gradient and otherwise
function accum!(A::TrackedArray)
isempty(A.tape) && return(A.deriv)
A.deriv .= sum(g(accum!(r)) for (r, g) in A.tape)
empty!(A.tape)
A.deriv
endWe can calculate the gradient by initializing the gradient of the result to vector of ones simulating the sum function
using FiniteDifferences
R.deriv .= 1
accum!(A)[1]
∇a = grad(central_fdm(5,1), a -> a*b + sin(a), a)[1]
A.deriv[1] ≈ ∇a
accum!(B)[1]
∇b = grad(central_fdm(5,1), b -> a*b + sin(a), b)[1]
B.deriv[1] ≈ ∇bThe api function for computing the grad might look like
function trackedgrad(f, args...)
args = track.(args)
o = f(args...)
fill!(o.deriv, 1)
map(accum!, args)
endwhere we should assert that the output dimension is 1. In our implementation we dirtily expect the output of f to be summed to a scalar.
Let's compare the results to those computed by FiniteDifferences
A = rand(4,4)
B = rand(4,4)
trackedgrad(A -> A * B + msin(A), A)[1]
grad(central_fdm(5,1), A -> sum(A * B + sin.(A)), A)[1]
trackedgrad(A -> A * B + msin(A), B)[1]
grad(central_fdm(5,1), A -> sum(A * B + sin.(A)), B)[1]To make the above AD system really useful, we would need to
Add support for
TrackedReal, which is straightforward (we might skip the anonymous function, as the derivative of a scalar function is always a number).We would need to add a lot of rules, how to work with basic values. This is why the the approach is called operator overloading since you need to overload a lot of functions (or methods or operators).
For example to add all combinations for +, we would need to add following rules.
function +(A::TrackedMatrix, B::TrackedMatrix)
C = TrackedArray(value(A) + value(B), "($(A.string_tape) + $(B.string_tape))")
push!(A.tape, (C, ∂C -> ∂C ))
push!(B.tape, (C, ∂C -> ∂C))
C
end
function +(A::AbstractMatrix, B::TrackedMatrix)
C = TrackedArray(A * value(B), "(A + $(B.string_tape))")
push!(B.tape, (C, ∂C -> ∂C))
C
endAdvantages:
Debugging and development is nicer, as AD is implemented in the same language.
The computation graph, tape, is dynamic, which makes it simpler to take the gradient in the presence of
ifandwhile.
Disadvantages:
The computation graph is created and differentiated during every computation, which might be costly. In most deep learning applications, this overhead is negligible in comparison to time of needed to perform the operations itself (
ReverseDiff.jlallows to compile the tape).The compiler has limited options for optimization, since the tape is created during the execution.
Since computation graph is dynamic, it cannot be optimized as the static graph, the same holds for the memory allocations.
A more complete example which allow to train feed-forward neural network on GPU can be found here.
Info
The difference between tracking and graph-based AD systems is conceptually similar to interpreted and compiled programming languages. Tracking AD systems interpret the time while computing the gradient, while graph-based AD systems compile the computation of the gradient.
ChainRules
From our discussions about AD systems so far we see that while the basic, engine, part is relatively straightforward, the devil is in writing the rules prescribing the computation of gradients. These rules are needed for every system whether it is graph based, tracking, or Wengert list based. ForwardDiff also needs a rule system, but rules are a bit different (as they are pushing the gradient forward rather than pulling it back). It is obviously a waste of effort for each AD system to have its own set of rules. Therefore the community (initiated by Catherine Frames White backed by Invenia) have started to work on a unified system to express differentiation rules, such that they can be shared between systems. So far, they are supported by Zygote.jl, Nabla.jl, ReverseDiff.jl and Diffractor.jl, suggesting that the unification approach is working (but not by Enzyme.jl).
The definition of reverse diff rules follows the idea we have nailed above (we refer readers interested in forward diff rules to official documentation).
ChainRules defines the reverse rules for function foo in a function rrule with the following signature
function rrule(::typeof(foo), args...; kwargs...)
...
return y, pullback
endwhere
the first argument
::typeof(foo)allows to dispatch on the function for which the rules is writtenthe output of function
foo(args...)is returned as the first argumentpullback(Δy)takes the gradient of upstream functions with respect to the output offoo(args)and returns it multiplied by the jacobian of the output offoo(args)with respect to parameters of the function itself (recall the function can have parameters, as it can be a closure or a functor), and with respect to the arguments.
function pullback(Δy)
...
return ∂self, ∂args...
endNotice that key-word arguments are not differentiated. This is a design decision with the explanation that parametrize the function, but most of the time, they are not differentiable.
ChainRules.jl provides support for lazy (delayed) computation using Thunk. Its argument is a function, which is not evaluated until unthunk is called. There is also a support to signal that gradient is zero using ZeroTangent (which can save valuable memory) or to signal that the gradient does not exist using NoTangent.
How can we use ChainRules to define rules for our AD system? Let's first observe the output
using ChainRulesCore, ChainRules
r, g = rrule(*, rand(2,2), rand(2,2))
g(r)With that, we can extend our AD system as follows
import Base: *, +, -
for f in [:*, :+, :-]
@eval function $(f)(A::TrackedMatrix, B::AbstractMatrix)
C, pullback = rrule($(f), value(A), B)
C = track(C)
push!(A.tape, (C, Δ -> pullback(Δ)[2]))
C
end
@eval function $(f)(A::AbstractMatrix, B::TrackedMatrix)
C, pullback = rrule($(f), A, value(B))
C = track(C)
push!(B.tape, (C, Δ -> pullback(Δ)[3]))
C
end
@eval function $(f)(A::TrackedMatrix, B::TrackedMatrix)
C, pullback = rrule($(f), value(A), value(B))
C = track(C)
push!(A.tape, (C, Δ -> pullback(Δ)[2]))
push!(B.tape, (C, Δ -> pullback(Δ)[3]))
C
end
endand we need to modify our accum! code to unthunk if needed
function accum!(A::TrackedArray)
isempty(A.tape) && return(A.deriv)
A.deriv .= sum(unthunk(g(accum!(r))) for (r, g) in A.tape)
endA = rand(4,4)
B = rand(4,4)
grad(A -> (A * B + msin(A))*B, A)[1]
gradient(A -> sum(A * B + sin.(A)), A)[1]
grad(A -> A * B + msin(A), B)[1]
gradient(A -> sum(A * B + sin.(A)), B)[1]Source-to-source AD using Wengert
Recall the compile stages of julia and look, how the lowered code for
f(x,y) = x*y + sin(x)looks like
julia> @code_lowered f(1.0, 1.0)
CodeInfo(
1 ─ %1 = x * y
│ %2 = Main.sin(x)
│ %3 = %1 + %2
└── return %3
)This form is particularly nice for automatic differentiation, as we have on the left hand side always a single variable, which means the compiler has provided us with a form, on which we know, how to apply AD rules.
What if we somehow be able to talk to the compiler and get this form from him?